
Your AI, your device,
your silicon.
Chat with Llama, Gemma 4, DeepSeek, Mistral and 100+ more — accelerated by your phone's NPU, your Mac's MLX engine, or any GGUF runtime. Completely offline. Completely free.

Models
Gemma 4 (E2B + E4B)
Apache 2.0, 128K context, bartowski GGUF. New SoTA local class. Gemma 4n with MTP speculative decoding — up to 2× faster on Android GPU.
Hardware
NPU on Snapdragon
QNN delegate via Play Feature Delivery. SoC-aware backend selection: QNN → GPU → CPU.
Platform
MLX on Apple Silicon
Real inference on macOS & iOS 18+ A17 Pro+. 1-bit quantisation — 7B in ~1.75 GB on Metal.
Agents
AI Agent Platform
On-device plan-and-execute agents with skills, schedules, and mobile tools. Your phone now serves /v1/chat/completions.
Why FluentAI?
The privacy-first AI agent platform that puts you in control
Privacy First
Your conversations never leave your device. No data collection, no tracking, no cloud required.
100+ AI Models
Run Llama, Gemma, DeepSeek, Mistral locally or connect to Claude, GPT-4, Gemini via cloud.
Voice Chat
Talk to AI naturally with 5 conversation modes — Normal, Interview, Learning, Storytelling, and Translation.
Completely Free
No $20/month subscriptions. Use powerful local models at zero cost, forever.
Knowledge Bases
Upload PDFs and documents to chat with your own data. On-device RAG with semantic search.
Tool Calling & MCP
Built-in tools for search, math, weather, and memory. Connect to GitHub, Slack, Notion via MCP.
Chat Organization
Folders, tags, pinning, branching, and search. Keep your conversations organized your way.
Export & Share
Export chats as text, Markdown, JSON, or even as audio podcasts. Share conversations anywhere.
Bring Your Own Model
Import any GGUF model or load directly from Hugging Face. Use any model you want — total freedom.
Multi-Runtime Engine
Same chat, three backends: GGUF, LiteRT, MLX. The app picks the fastest one for your device automatically.
NPU Acceleration
Snapdragon NPU via QNN delegate. 2–4× faster local inference on supported phones with lower battery drain.
Apple Silicon MLX
Native Metal-backed inference on M-series Macs and A17 Pro+ iPhones. No Rosetta. No fallback. 1-bit quant unlocks low-RAM devices.
OpenAI-Compatible Servers
Point at LM Studio, vLLM, LocalAI, Jan, or any /v1/chat/completions endpoint. Models auto-discover.
On-Device AI Agents
Plan-and-execute agents with task memory run entirely on-device. Schedule agents, use mobile tools — clipboard, calendar, contacts, files.
Hugging Face Browser
Search and filter 10,000+ GGUF models by runtime. Per-file download with memory-fitness badges so you don't OOM your phone.
Benchmark + MMLU-50
4-step wizard, MMLU-50 quality score, shareable PNG + Markdown result cards, filterable history. Decode-only tok/s for honest speed reporting.
One app. Three inference engines.
FluentAI automatically picks the fastest runtime for your hardware — GGUF on every device, LiteRT for Snapdragon NPU/GPU, and MLX for Apple Silicon.
FllamaRuntime
// GGUF · llama.cpp · everywhere
- →Gemma 4 architecture backport (ISWA dual-cache, MoE 128 experts)
- →KleidiAI v1.23.0 (SME2 + Q4_K paths)
- →KV cache TQ4/TQ3 quantization
- →16 KB page alignment for Android 15+
LiteRTRuntime
// Android · GPU / NPU · LiteRT-LM 0.10
- →Snapdragon NPU via QNN delegate
- →SoC-aware backend selection: QNN → GPU → CPU
- →Play Feature Delivery — no bloat at install
- →MTP speculative decoding — ~1.5–2× faster generation
MlxRuntime
// macOS · iOS 18+ A17 Pro+ · Apple Silicon
- →Real Apple MLX inference on M-series + A17 Pro+
- →1-bit quantisation — 7B models in ~1.75 GB
- →Metal-native — no Rosetta, no fallback
- →Multi-file parallel download from Hugging Face
Powerful Capabilities
More than just a chat app — FluentAI is a complete AI toolkit

Chat With Your Documents
Upload PDFs, text files, and documents to create knowledge bases. FluentAI uses RAG (Retrieval-Augmented Generation) to search and answer questions from your files — all processed on-device.

Built-in Tools & MCP
FluentAI comes with built-in tools — calculator, web search, weather, date/time, and AI memory. Plus full Model Context Protocol (MCP) support to connect to GitHub, Slack, Notion, and 20+ other services.

Rich Content & Code
Beautiful syntax-highlighted code blocks, LaTeX math rendering, HTML/SVG previews, and full Markdown support. Perfect for developers, students, and researchers.

Templates & AI Personas
Choose from built-in prompt templates or create your own. Set up custom AI personas with unique system prompts — from a coding assistant to a creative writing partner.

Truly Cross-Platform
Available on Android today with iOS, Windows, macOS, Linux, and Web coming soon. Your AI assistant, on every device you own.
Works with your favourite models — and your favourite server
Run models locally on your device, connect to cloud providers, or point at any OpenAI-compatible server — your choice
Llama 3
On-deviceGemma 4 E2B / E4B
Google · Apache 2.0
On-deviceDeepSeek
On-deviceMistral
On-devicePhi
On-deviceQwen
On-deviceClaude
Anthropic
CloudGPT-4
OpenAI
CloudGemini
OpenRouter
200+ models
CloudLM Studio · vLLM · LocalAI · Jan
Any /v1 endpoint
OpenAI-compatOllama
Local server
InfrastructureSee it in action
A beautiful, intuitive interface designed for seamless AI conversations
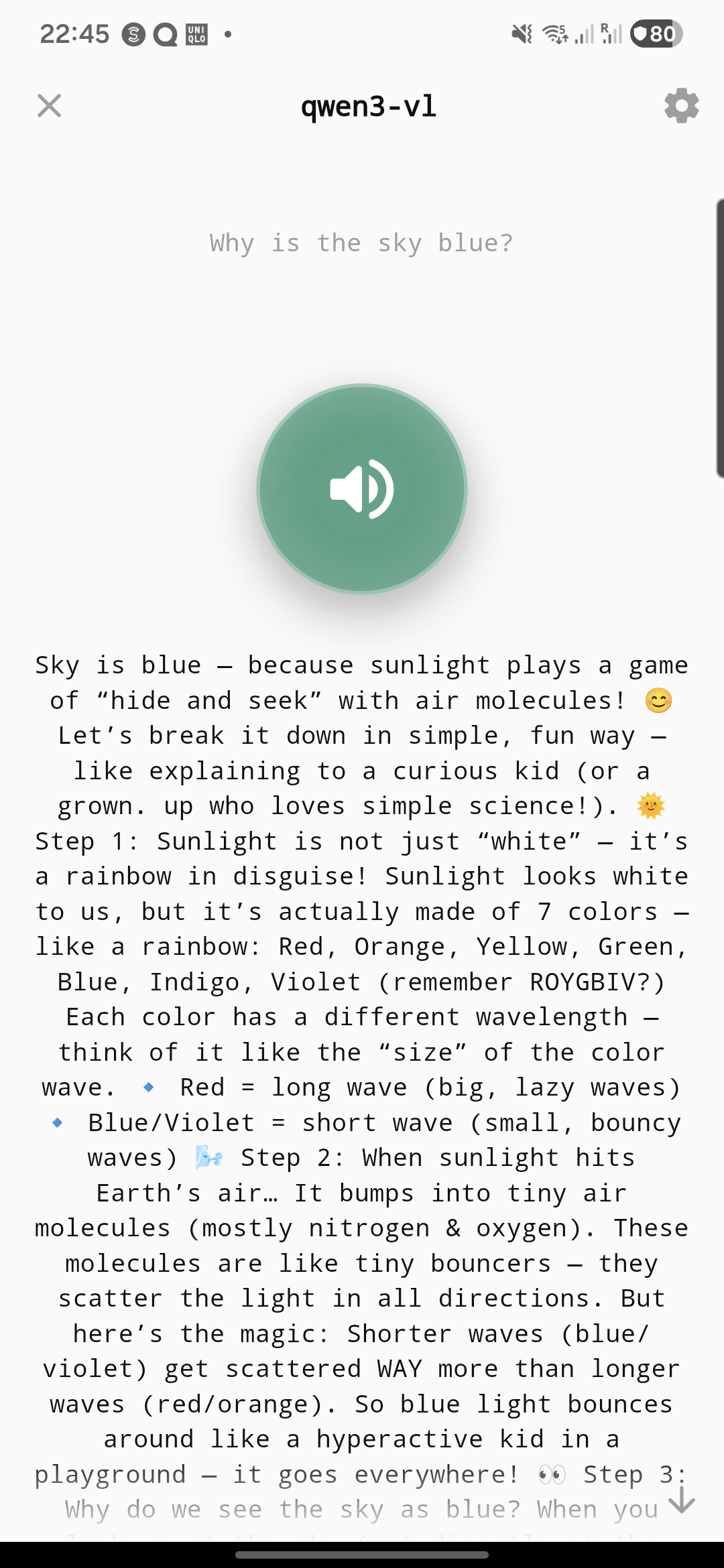
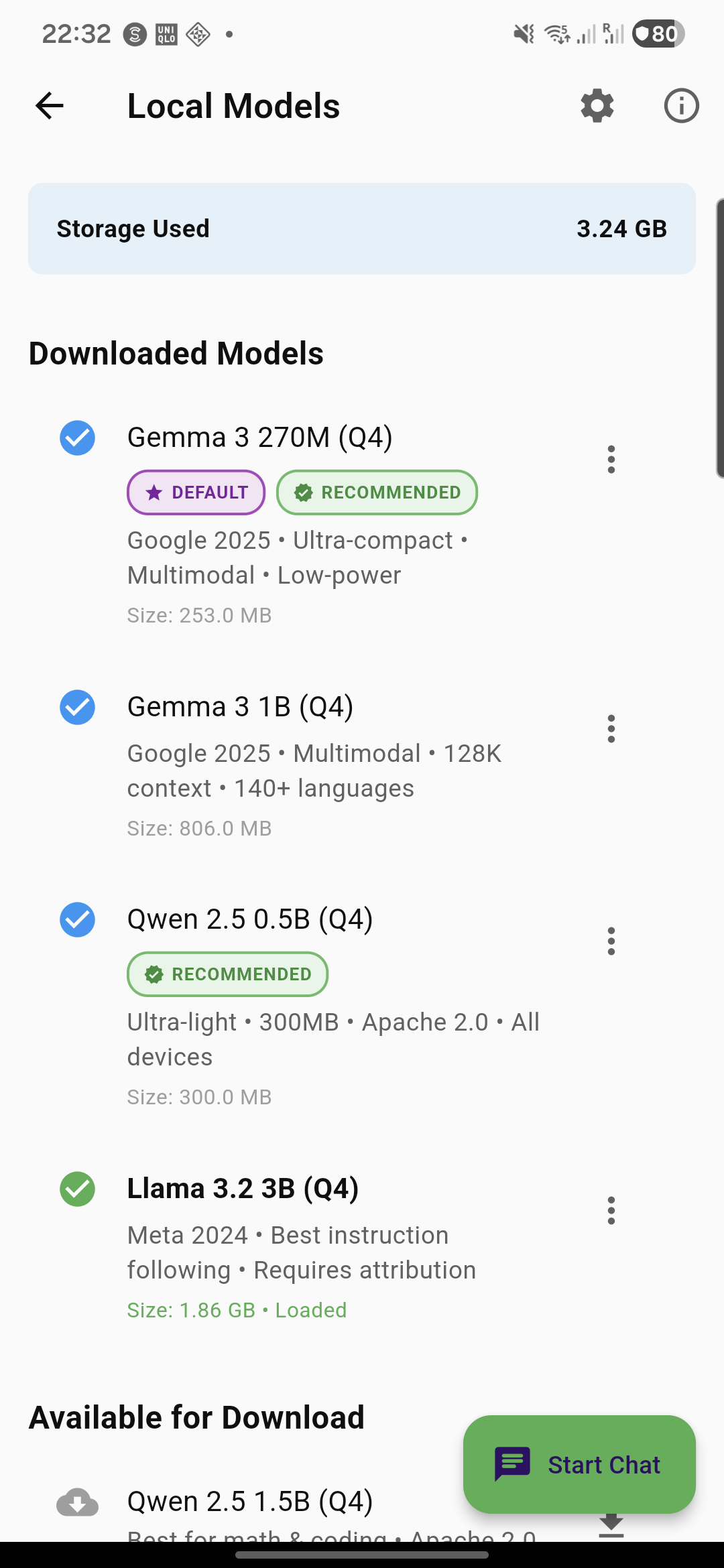
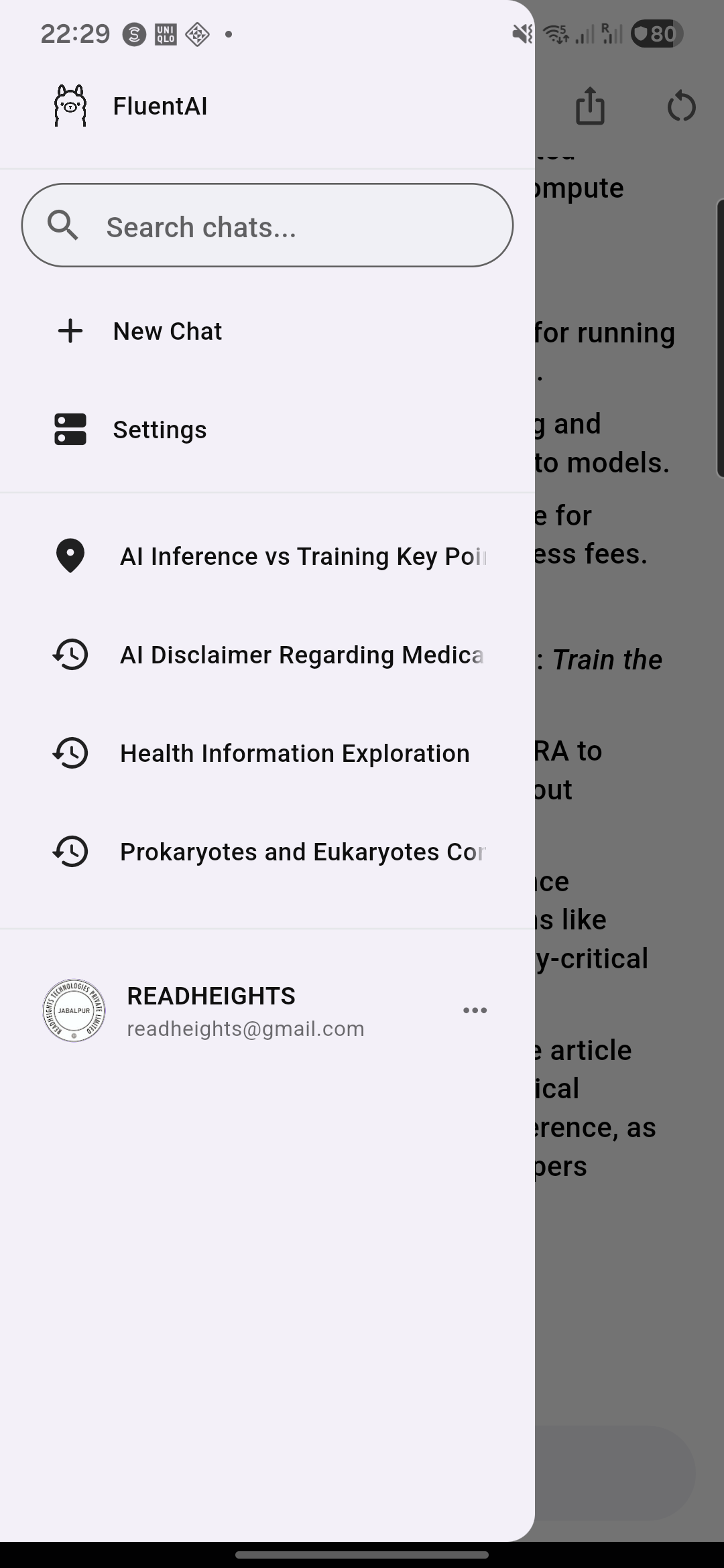
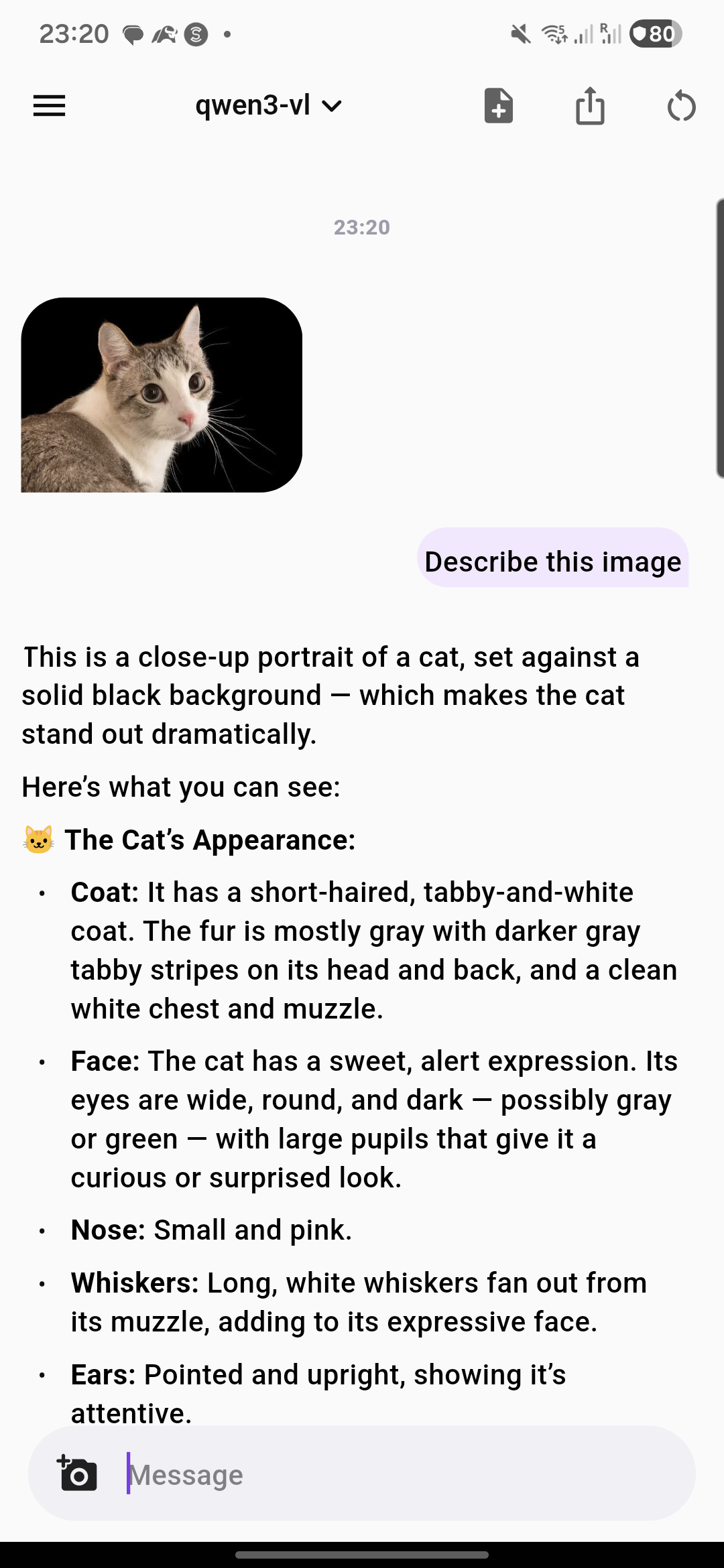
Your data stays on your device
FluentAI is built from the ground up with privacy as the foundation, not an afterthought
Zero Data Collection
No telemetry, no tracking, no analytics. Your conversations are yours alone.
Offline Capable
Run AI models entirely on your device. No internet connection needed.
Open Source
Audit the code yourself. Full transparency in how your data is handled.
How FluentAI compares
Hardware acceleration, BYO servers, and on-device privacy — the moats the cloud apps can't match
| Feature | FluentAI | ChatGPT | Claude | Gemini |
|---|---|---|---|---|
| Price | Free (local models) | Free / $20/mo | Free / $20/mo | Free / $20/mo |
| Privacy | On-device, zero collection | Cloud, data used for training | Cloud-based | Cloud, data used for training |
| Offline Mode | ✓ | ✗ | ✗ | ✗ |
| Model Choice | 100+ models | GPT-4 only | Claude only | Gemini only |
| Hardware AccelerationNEW | NPU + GPU + Metal + CPU | Cloud only | Cloud only | Cloud only |
| BYO Local ServerNEW | LM Studio · vLLM · LocalAI · Jan · Ollama | ✗ | ✗ | ✗ |
| BYO Model (GGUF / HF)NEW | ✓ | ✗ | ✗ | ✗ |
| Voice Chat | ✓ | Paid | ✗ | ✓ |
| Open Source | ✓ | ✗ | ✗ | ✗ |
Frequently Asked Questions
Everything you need to know about FluentAI